
In our previous blog, Supervised vs Unsupervised Learning, we learned that Machine Learning consists of algorithms that learn to solve a problem without expressly being provided step by step instructions by a human agent. Then we differentiated between two major categories of algorithms – Supervised Learning & Unsupervised Learning.
In supervised learning, the training data consists of both input and corresponding expected output for the given input. This output thus acts kind of feedback or ‘supervision’ to help adjust the model parameters or, in other words, ‘teach’ the model. In contrast, unsupervised learning lacks any such feedback and highlights the underlying pattern or structure in the input alone.
Now given all that, here is a question for you: Consider how, as humans, do we learn to play most video games by ourselves without ever receiving any instructions from an expert? To which category does such a self-learning algorithm belong to – supervised learning or unsupervised learning?
Reinforcement Learning Introduction
To answer this question, let’s explore further the nature of the problem. Even though there is no supervision involved traditionally, an auto-learning bot would not be complete without any feedback. The rewards and punishments within the game itself can provide sufficient feedback from time to time. A simple score maximizing strategy should lead a bot to learn to avoid or kill enemies, collect coins, clear levels, and reach any objectives. As you might have correctly guessed, this problem doesn’t neatly fit into either category of supervised or unsupervised learning and instead falls under a third category: Reinforcement Learning.
Updated below, thus, are the three broad categories of Machine learning algorithms:
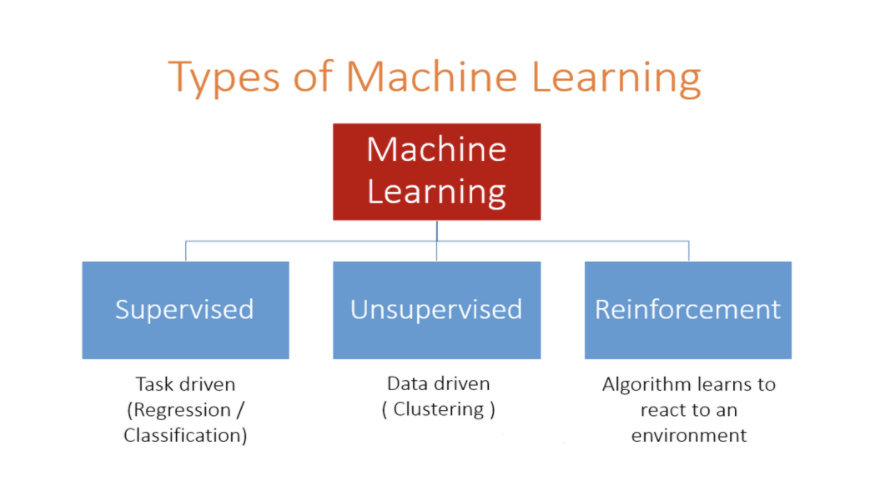
(Just for the sake of completeness, it is worthwhile to mention that a bot can also be trained to play a video game as a supervised learning problem. For this, it will require several hours of recording of a human agent playing the game. Then we can use the state and actions from this recorded data to train our model.)
Reinforcement Learning algorithms involve learning to take corrective actions in an environment to maximize a cumulative reward. If you consider much of human learning happens in the form of reinforcement learning from learning to walk, drive, ride a bicycle, playing sports, and much else. The popular industrial applications of reinforcement learning include self-driving cars and robotic motion control.
Definitions
Formally, a reinforcement learning problem is a Markov Decision Process. The learner and decision-maker is called the agent. The thing it interacts with outside the agent is called the environment. The agent interacts with the environment in discrete time steps. The configuration of the environment (along with that of the agent) at a time instant “t” can be called the state of the environment denoted by “st.” Given this state “st,” the agent chooses an action, “at,” from a set of available actions and receives an immediate reward “rt” (may be zero or negative), while the state transitions from “st” to “st+1”. The interaction continues, thus giving rise to a sequence or trajectory that begins like this:
s0, a0, r0,s1, a1, r1,s2, a2, r2,s3, a3, …
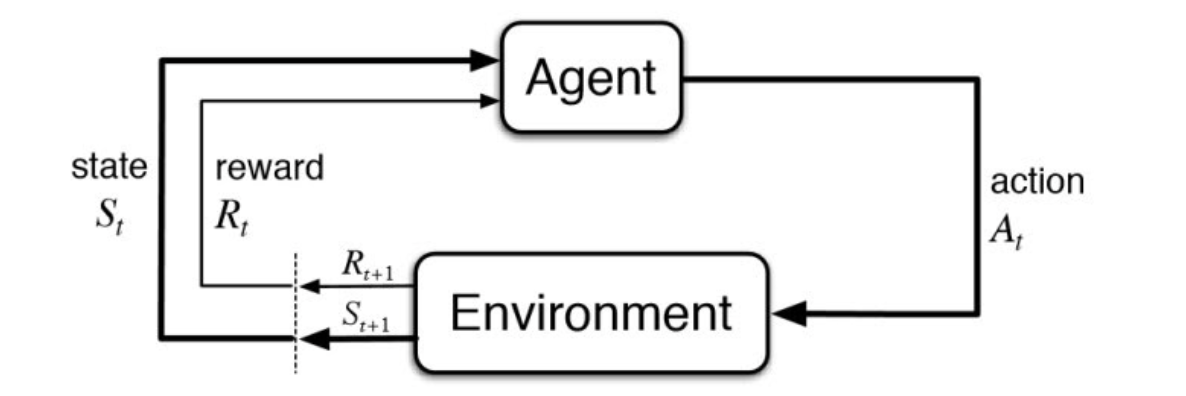
The agent’s goal is to follow a trajectory to maximize the cumulative reward r1, r2, r3, and so on.
Learning Process
Each state-action pair is mapped to a probability number. This map is called the Policy represented as the following function:
π(a, s) = P(at = a | st = s)
The value function of a state “s” under a policy “π,” denoted “Vπ(s),” is the expected return (expected value of the sum of discounted returns starting from the state “s”) when starting in “s” and following “π” thereafter.
The learning process requires the algorithm to find a policy that maximizes the expected return. This optimal policy is then used to play the game.
There are multiple algorithms to achieve this optimization. We shall discuss in the next blog(s) some of these:
- Q-learning
- Deep Q-learning
- Policy Gradient
Did you enjoy this content? Follow our linkedin page!