
Brian Krebs is a good guy (and a “good-guy”), but seeing a post from him on Friday afternoon usually isn’t a good thing.
Last Friday it was the Okta breach.
As a CISO, I had to look and see if we were impacted. It was very unlikely — we weren’t notified by Okta, and as an early stage vendor, we were not a prime target. But based on my past experience running global security operations at a F100 Life Sciences and F100 Food and Beverage company — where the most important measure of time is how long it takes to get a phone call from upstairs asking if we were impacted — I jumped in.
In light of the disclosure article, Okta published a list of IOC’s; a bunch of IP addresses and some user-agent strings that might indicate suspicious activity.
Initially, I wanted to measure how long it would take me to do this in the tools natively without any form of centralization. There were 23 IP addresses and two user-agent strings. Small-ish in relative terms for a list of IOCs, but that’s still 23 different searches in one technology if it doesn’t support multiple chained queries with search operators like “OR”.
I took those IP’s, opened CrowdStrike, Amazon CloudFront, Google Workspaces, and JumpCloud (our SSO & MDM solution), and searched to see if they were in any of the indicators in the logs. I’d open a tab for each, log in individually, and search. I don’t want to trivialize the word “search”. Each of the technologies above has a different way of searching for “source IP address” in them. I know enough about each to craft a search off the top of my head — no manual needed — but some of the syntax got a bit sticky.
Those queries would look something like this:
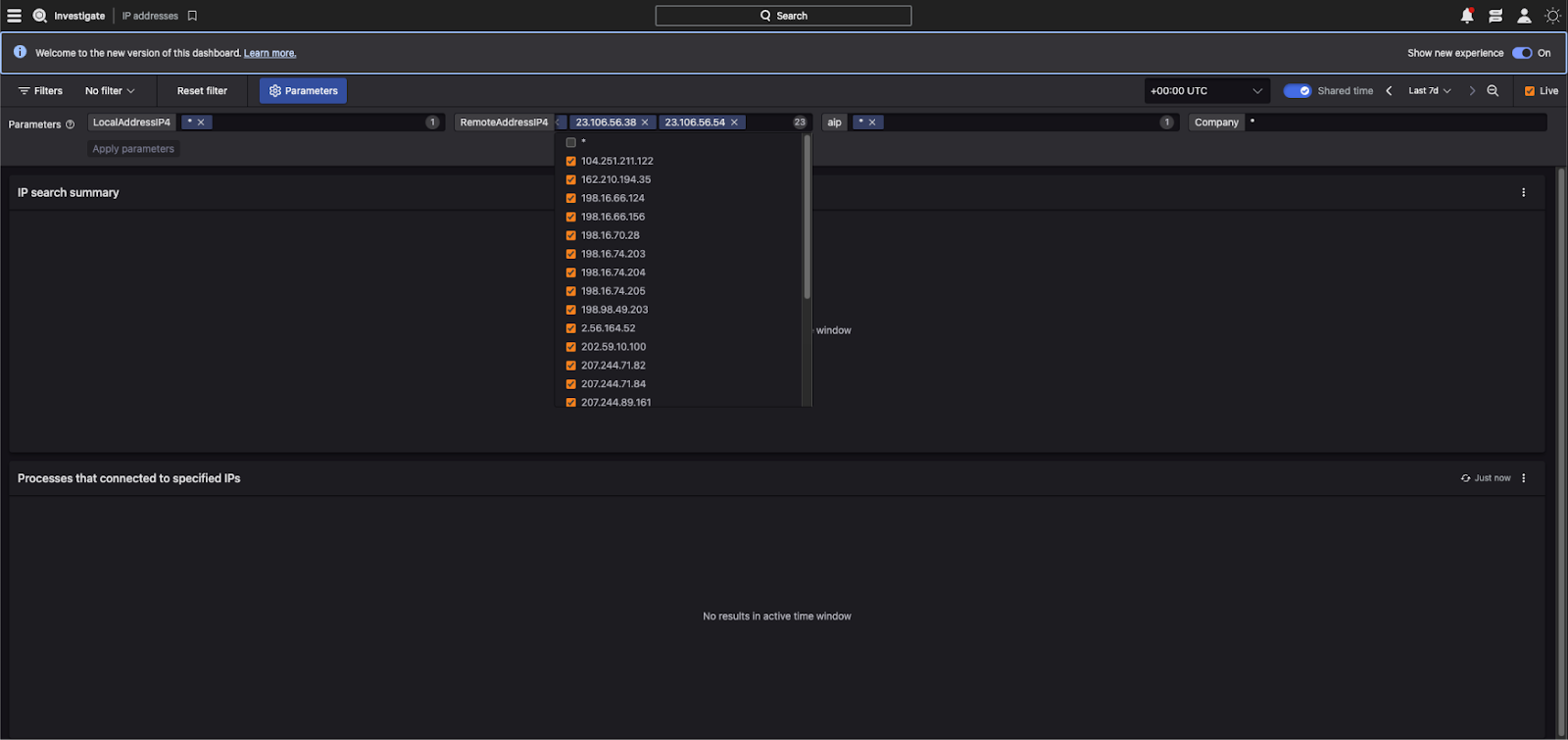
Ok — CrowdStrike’s new UI makes it look pretty easy, but let’s look at their Advanced Event Search Window:
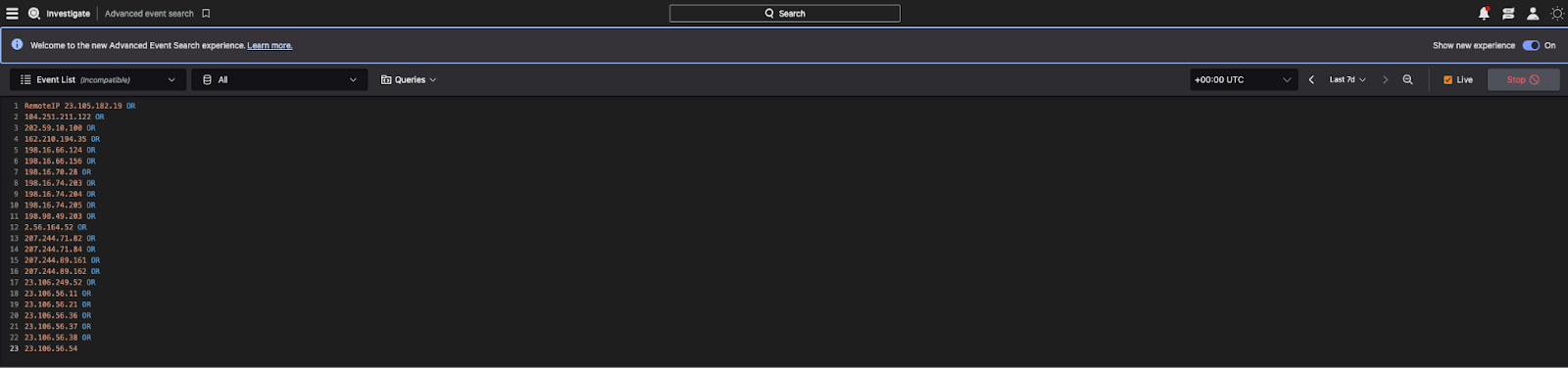
Gets to be a bit more tedious, but the only real challenge is formating the strings to put them into their search bar.
Attempting to look through our CloudFront access logs proved to be much more challenging.
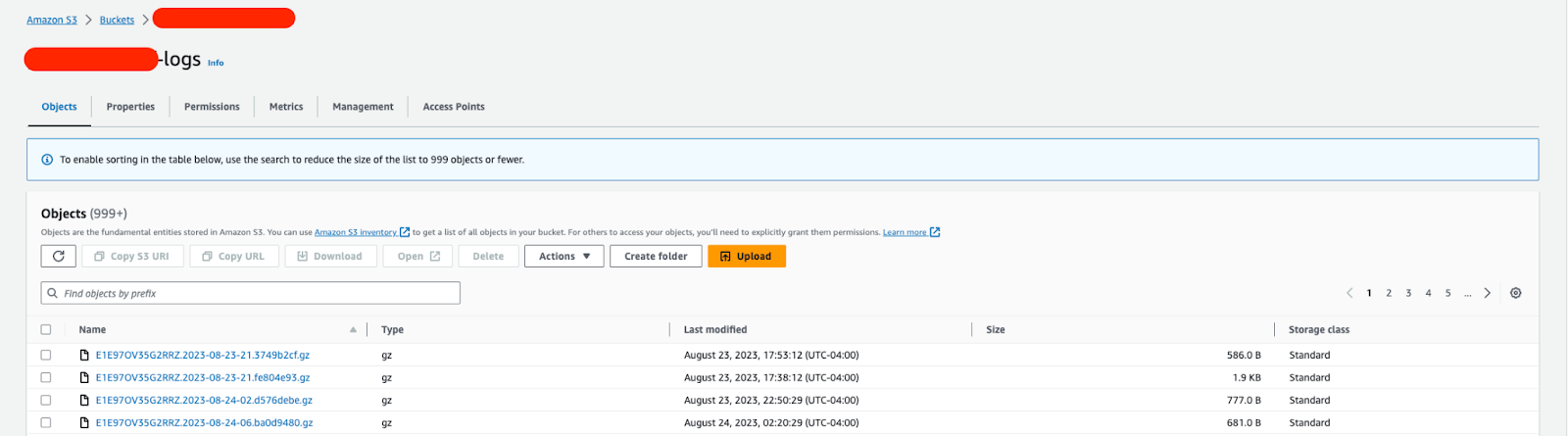
AWS doesn’t make this easy. If you were part of a security organization looking at your CloudFront logs, you would probably be looking at downloading the zipped files for the days in question, or the last 7-14 days, and using something like grep to search through all the logs. This endeavor took the longest.
Call it about an hour to get to “ready for the bad phone call” mode at Query. If I had been at a bigger shop (one of my larger networks had 250k+ endpoints in the environment), it would have taken 2-3 hours. And if I found something, it would multiply the time as I pivoted back into search mode, as I would have to anticipate all the follow-on questions and impacts.
Of course, at Query, I try to eat my own dog food whenever I can. So I looked at how I would do this in Query.
CrowdStrike is a supported integration into Query. This means the Crowdstrike data is available in a Query search with no additional actions. You just put in the CrowdSrike API information and you’re off to searching (literally 30 seconds of work from start to finish).
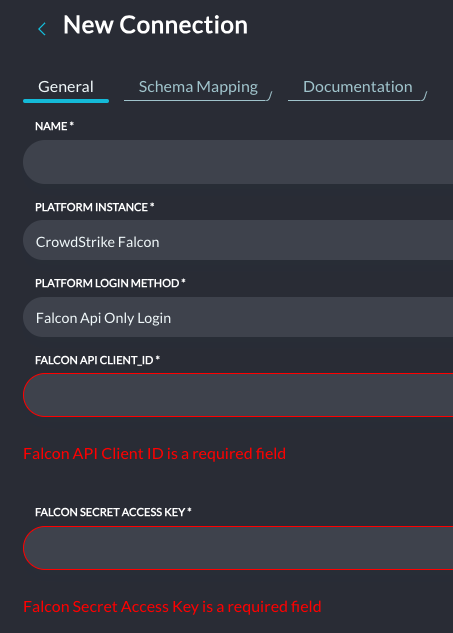
Query also has an integration for Amazon S3 Buckets…so I could use Athena to wrap the S3 buckets being used for my CloudFront access logs to search those. And boom, they were now in Query via the S3 integration. Turns out this is a successful workaround for most applications. If it can export log data, you can quickly get it into S3 and you can be up and running with Query in minutes.
No such luck with Google Workspaces, though. The S3 trick doesn’t work for them. I made sure they are on the integration roadmap and checked the old fashioned way.
All this took less than 10 minutes. So I hit search, which meant with one search request I was looking at all my CrowdStrike and CloudFront data at the same time. And I found…nothing! Cool.
Time saved? 60 minutes vs 10 minutes with Query.
As an early stage startup, of course we have lots to work on, but hit me up if you want to take a few minutes to hook Query up to your environment. You could end up with valuable time back in your day, and hopefully you end up finding nothing too.